Evidently AI - 監測模型準確度與資料偏移
Evidently是一個能夠偵測資料偏移與更近一步評估模型訓練好壞的Python套件,透過大量的互動式圖表能夠對資料集與模型有更深入的了解
Install
For Python and Colab
pip install evidently
For Jupyterlab
$ jupyter nbextension install --sys-prefix --symlink --overwrite --py evidently
$ jupyter nbextension enable evidently --py --sys-prefix
Quick Example
下面用四個小部分來快速演示一下這個套件能做到什麼樣的效果
Import Dataset and Packages
import pandas as pd
from sklearn import datasets
from evidently.test_suite import TestSuite
from evidently.test_preset import DataStabilityTestPreset
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset
iris_data = datasets.load_iris(as_frame='auto')
iris_frame = iris_data.frame
Run Test and Get Report
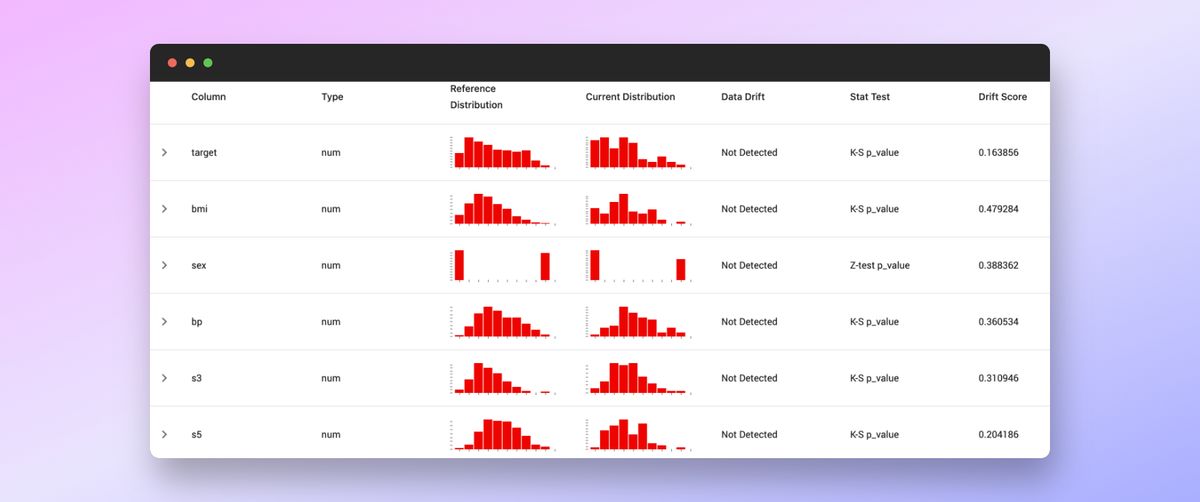
這裡快速比較data中前60筆和後60筆的分佈有沒有差很多,預設的column名稱會需要id, datetime, target, prediction,如果要改成不同的column名稱就得在column_mapping的地方帶入相對應的dictionary
data_drift_report = Report(metrics=[
DataDriftPreset(),
])
data_drift_report.run(current_data=iris_frame.iloc[:60], reference_data=iris_frame.iloc[60:], column_mapping=None)
data_drift_report
Report的話在Jupyterlab會以互動的形式呈現,裡面可以選擇各種不同的preset來觀察資料或是模型
Save Reports to Other Format
可以把檔案存成HTML以方便不是用Jupyterlab或是colab開發的用戶做觀看,如果未來要用其他隻程式讀取的話也可以存成JSON檔
data_drift_report.save_html('report.html')
data_drift_report.save_json('report.json')
Features
目前提供的report preset大致分為底下幾種
Data Quality
data_stability= TestSuite(tests=[
DataStabilityTestPreset(),
])
data_stability.run(current_data=iris_frame.iloc[:60], reference_data=iris_frame.iloc[60:], column_mapping=None)
data_stability
Data & Target Drift
如果資料在不同代之間的差異過大表示模型的準確度很可能會不夠可靠

Regression Model Quality
可以透過report來確認regression模型的準確度並查出不準的原因
reg_performance_report = Report(metrics=[
RegressionPreset(),
])
reg_performance_report.run(reference_data=ref, current_data=bcur)
reg_performance_report
有給reference_data的話報告會產生十幾種的圖表,底下介紹一些我個人在實際ML Project中比較常會用到的
Real and Prediction Plot
這種圖有分成by datetime的與沒有by datetime,沒有by datetime的圖就是scatter plot

如果沒有by datetime就會產生by index的,通常by index的圖會比較看不出關係

還有一種是可以透過個別feature去檢查預測的結果

Residual Plot
這種圖只有by datetime的

也有percentage版

Error Distribution

Summary
最大的好處在於使用非常少的code就能夠去觀察資料以及衡量資料、模型的穩定性,算是一個在ML專案前期以及上線後都會需要的套件
目前資料的檢測還不包含outlier的detection,算是一個小小美中不足的地方,如果未來補齊了就能快速觀察每套到手上的資料